
Big data testing 101: the complete guide
By generating a drastic amount of data, the Internet is somewhat a Pandora’s box. IDC predictions state that the worldwide data ecosystem will grow by 3.8 times and reach 175 ZB by 2025. Wow, right?
With that, data storing and its accurate processing become much more challenging. Here’s the need to apply novel tools for big data scenarios.
Let’s take a trip back in time. Nearly a decade ago, forward-thinking companies included big data initiatives in their strategies. Today, 96% of big data efforts yield tangible results and help strengthen business continuity.
How did they succeed in addressing big data issues? They introduced a big data strategy with big data testing at the core.
Let’s delve deep into each step to enable error-free data handling and let’s explore the benefits that companies get by applying QA.
Step 1. Pre-define big data testing strategy and its objectives
Step 2. Consider big data testing essentials
Step 3. Perform mission-critical testing types
Step 1. Pre-define big data testing strategy and its objectives
McKinsey report indicates that data-driven companies are:
- 23X more likely to attain new users
- 6X more likely to reinforce customers’ loyalty
- 19X more likely to increase revenue.
A comprehensive big data strategy is one of the clues to such business prosperity. Defining QA activities beforehand helps reach 5 core data traits — accuracy, completeness, reliability, relevance, and timeliness.
With QA, organizations ensure high data quality and consistency while properly forecasting market requirements and effectively analyzing customers’ expectations.
Once having tested big data architecture, its components, and their interaction with each other, companies optimize budget on data storage.
What’s more, well-structured data and its timely processing help build effective business strategies and make sound decisions while reaching desired outcomes.
Step 2. Consider big data testing essentials
Databases, internal ERP/CRM systems, weblogs, social media — these and many other sources transfer information to big data systems.
Data comes in 3 ways: structured, semi-structured, and unstructured. As unstructured data forms prevail, it’s getting more difficult to collect and store it due to complex converting processes. Only 0.5% of unstructured data across the globe is analyzed and used today.
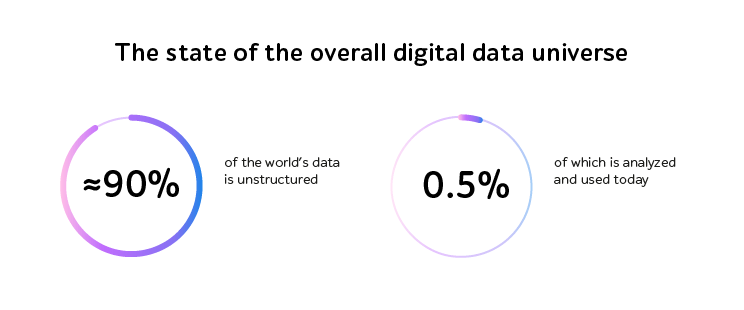
Source: www.analyticsinsight.net
To verify that data is processed accurately, the good strategy is to follow these three stages:
- Data ingestion testing. To check that data is pulled into the system correctly, corresponds to the original values, and is extracted to the right location.
- Data processing testing. To dodge any data discrepancy by asserting the business logic of ingested data and comparing output and input results. If used, test automation helps facilitate the verifying process and shorten the testing time.
- Validating the outputs. To test further data transmitting to other more specific DBs that track customers’ feedback, internal processes, financial reports, etc., and check transformation logic as well as coinciding key value pairs.
Step 3. Perform mission-critical testing types
High adoption of big data programs across enterprises is to push applying big data testing and proper data management. With that, the big data testing market size is expected to grow from $20.56 billion in 2019 by a CAGR of 8.53% during 2020-2025.
While the worldwide volume of information is rising exponentially in turn, organizations face issues with defining test approaches for structured and unstructured data forms, configuring suitable test environments, ensuring data integrity and security.
To navigate these and other critical big data challenges, we offer to include these checks into the QA strategy:
End-to-end testing
To eliminate duplicates, inconsistent information, non-corresponding values, overall poor data quality and ensure continuous data availability, QA engineers perform end-to-end testing while validating business logic and layers of the big data app and ascertaining there are no missing values.
Integration testing
QA specialists verify that interaction between each of the thousands of modules, sections, and units is well-tuned while avoiding errors affecting the entire data storage.
Architecture testing
Within processing intensive resources round the clock, it’s vital to check that a big data app has a proper architecture that doesn’t provoke performance degradation, node failures, high data latency, and a need for expensive data maintenance.
Performance testing
Enormous data sets — with little time to process them. That means QA specialists verify that big data systems are able to withstand a heavy load as well as receive and handle voluminous information at short notice. Performance testing engineers are to check how fast each system’s component consumes various data forms, processes acquired files, and retrieves them.
Cybersecurity testing
While getting sizable volumes of customers’ sensitive data, it’s pivotal to minimize the risks of cyberattacks as they are becoming more sophisticated. To imitate cybercriminals’ behavior while creating real-life conditions and preventing data leakage, QA engineers execute penetration testing that helps ensure the system’s resistance to viruses, malware, and other kinds of tampering.
Test automation
“I’ve covered the entire big data system with manual testing.” Sounds kind of like a science fiction episode, right? This is why test automation is of help to reduce human errors and free up time and efforts for high-priority tasks. The thing to remember is that not each and every check can be automated — if a feature can be checked frequently and isn’t likely to change in several weeks, it’s worth automating.
Summing up
To respond to today’s high pace of the IT market and the drastically growing amount of data, companies are actively introducing big data initiatives.
When applying comprehensive big data testing, organizations are more likely to succeed while accurately predicting customers’ behavior patterns, effectively making business decisions, and strengthening their competitive advantage.
Feel free to get hold of the a1qa team to get professional QA support for your big data solution.








